
Bulk Prompt Testing Across LLMs: Enterprise AEO Platform Features

By Sean Dorje, Co-Founder/CEO of Relixir - Inbound Engine for AI Search | 10k+ Inbound Leads delivered from ChatGPT · Nov 26th, 2025
Bulk prompt testing enables enterprises to validate AI responses across multiple LLMs simultaneously, replacing manual QA cycles that took weeks with automated pipelines completing in hours. Modern frameworks validate prompts across diverse datasets, providing empirical accuracy scores while research demonstrates 30-40% fewer mistakes when using multi-model verification compared to single-model runs.
Key Facts
Multi-model orchestration runs identical prompts through OpenAI, Google, Anthropic, xAI, Perplexity, and OpenRouter simultaneously for cross-verification
Automated evaluation pipelines eliminate manual labeling using algorithmic scoring that scales across thousands of test cases
Enterprise platforms process 6 million+ prompts daily with 25-40% AI visibility improvement within 60 days
API providers may modify models through quantization or finetuning without notifying users, making continuous testing critical
Budget-aware optimization frameworks achieve 57% stability improvement with minimal computational overhead below 1%
Compliance tools encode approximately 400 regulatory clauses from EU AI Act, GDPR, and ISO/IEC 42001 standards
Bulk prompt testing is the only scalable way for enterprises to understand how every major LLM will answer high-stakes customer questions. In 2025, the practice has moved from ad-hoc spot checks to fully automated pipelines that cut QA cycles from weeks to hours.
Why Bulk Prompt Testing Matters for AEO in 2025
The landscape of Answer Engine Optimization has fundamentally shifted. As manual accuracy monitoring proves insufficient for enterprise needs, organizations are turning to systematic testing approaches. Microsoft's batch testing framework now validates prompts across diverse datasets, providing empirical accuracy scores that build trust in AI tools.
AEO itself has evolved from simple keyword tracking to comprehensive citation analysis. It's no longer about whether your content appears. The focus has shifted to structuring content so it becomes a cited source in AI-powered tools like ChatGPT, Perplexity, and Google Gemini.
For enterprises managing thousands of prompts across multiple models, manual testing simply cannot keep pace with the speed of AI evolution. The stakes are particularly high when API providers modify underlying models through quantization, watermarking, or finetuning. These changes often happen without notifying users. This makes bulk testing not just a convenience but a critical compliance requirement for maintaining consistent AI outputs across enterprise applications.
How Does Multi-Model Orchestration Reduce Errors?
Multi-model orchestration fundamentally changes the error equation by running identical prompts through multiple LLMs simultaneously. TachiBot's implementation demonstrates this approach in action: models from OpenAI, Google, Anthropic, xAI, Perplexity, and OpenRouter check each other's work, debate solutions, and catch errors before they reach users.
PolyPrompt enables enterprises to leverage all their API subscriptions simultaneously, getting maximum value by comparing outputs across providers. This parallel processing approach isn't just about redundancy. It leverages each model's unique strengths while mitigating individual weaknesses.
OpenAOE's framework takes this further by supporting both commercial and open-source LLMs in group chat scenarios. The platform can return multiple LLM answers simultaneously from a single prompt, enabling real-time comparison and validation across diverse model architectures.
Common orchestration patterns that enterprises deploy include:
Parallel verification: Running prompts through 3-5 models simultaneously
Multi-round debates: Models argue for 3-200 rounds to refine solutions
Adversarial challenges: Built-in challenger tools find logical flaws
Consensus voting: Models vote on answers with configurable thresholds
Selective tool activation: Toggle specific capabilities based on use case
Error-Reduction and ROI Metrics
Research shows "30-40% Fewer Mistakes" when using multi-model verification compared to single-model runs. Real benchmarks demonstrate 30% latency reduction, 10% fewer hallucinations, and improved code generation quality. These improvements translate directly to bottom-line impact: reduced customer complaints, faster incident resolution, and decreased manual review overhead.
The ROI becomes even more compelling when considering the alternative. A single AI model can confidently provide wrong answers without knowing when it's making things up. Multi-model orchestration transforms this uncertainty into measurable confidence scores. This enables enterprises to set quality thresholds appropriate for their risk tolerance.
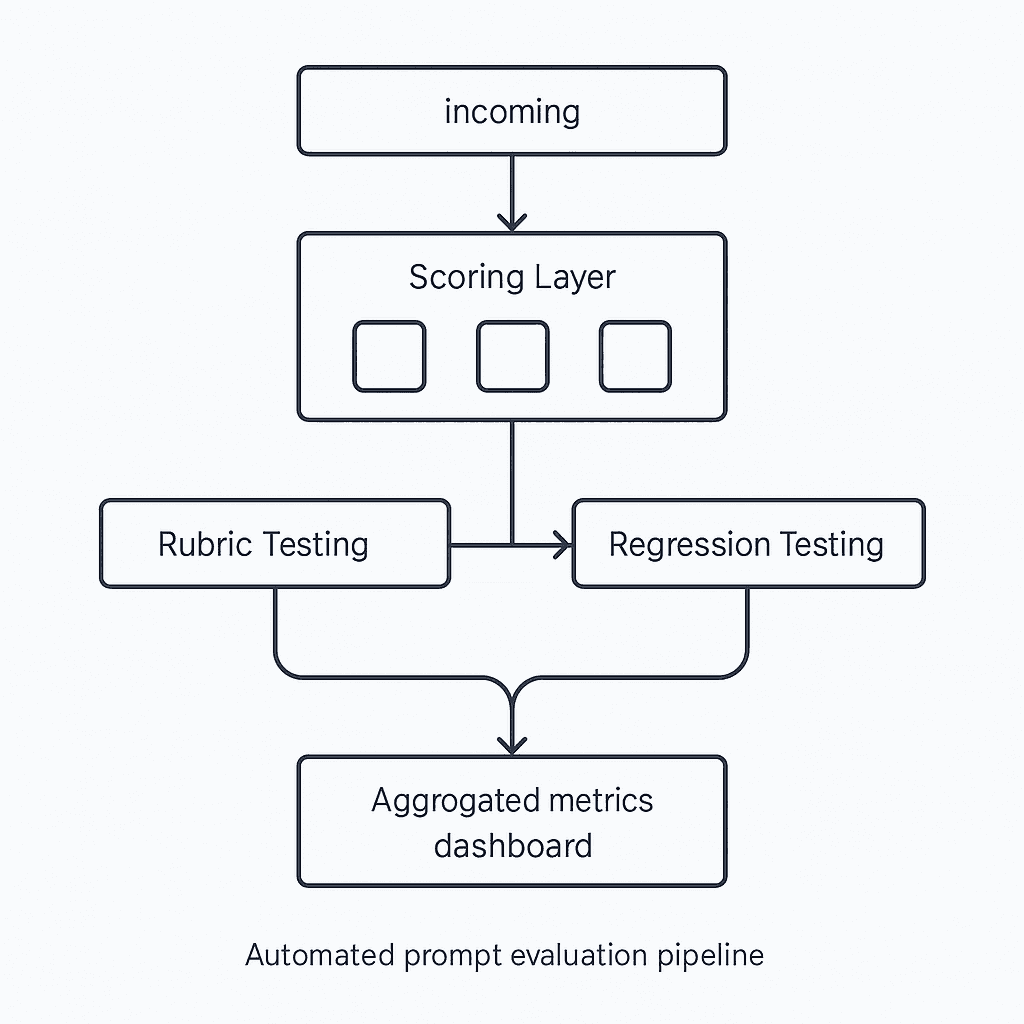
What Are Automated Prompt Evaluation Pipelines?
Deepchecks streamlines evaluation by configuring auto-scoring pipelines that work during development, CI/CD, and production. Their algorithmic backbone uses small language models and multi-step NLP pipelines working together through Mixture of Experts techniques to simulate intelligent human annotators.
Patronus provides industry-leading models for scoring RAG hallucinations, image relevance, and context quality. Their Glider model delivers fine-grained rubric-based scoring with explainable evaluation and multilingual reasoning support, enabling continuous monitoring without manual labeling.
ACEBench addresses critical limitations in existing benchmarks by categorizing evaluation into Normal, Special, and Agent scenarios. This granular approach tests basic tool usage, ambiguous instructions, and multi-agent interactions. The result is a comprehensive view of LLM capabilities that single-metric evaluations miss.
These automated pipelines eliminate the measurement problem that plagues LLM applications. Instead of relying on subjective expert review, platforms now provide objective, repeatable scoring that scales across thousands of test cases. This shift from manual to automated evaluation represents a fundamental change in how enterprises validate AI outputs.
How Can Enterprises Scale Prompt Management & Optimization?
PromptLayer serves as middleware for managing LLM prompts at scale, supporting over 9,000 users including AppSumo and Speak. The platform combines CMS-like version control with production monitoring tools, enabling granular tracking across 40+ language models.
TRIPLE leverages multi-armed bandits to optimize prompts under budget constraints, significantly outperforming existing methods while adhering to financial limitations. This framework can be directly integrated into existing pipelines like APE and APO, enhancing their performance without complete overhauls.
IPOMP improves effectiveness by 1.6% to 5.3% using semantic clustering and boundary analysis, followed by iterative refinement with real-time model performance data. The approach achieves at least 57% stability improvement with minimal computational overhead below 1%.
Gartner projects end-user spending on generative-AI models will reach $14.2 billion in 2025, making efficient prompt management critical for ROI. By 2028, 33% of enterprise software will include agentic AI, with at least 15% of work decisions made autonomously.
IDC's research confirms this trend toward autonomous AI-driven workflows that minimize downtime and human effort. Organizations must implement systematic prompt management to handle this scale effectively.
Key optimization levers enterprises should implement:
Version control with rollback: Track prompt iterations with side-by-side comparisons
Regression testing frameworks: Validate changes against historical datasets
Performance analytics suites: Monitor latency and token usage in real-time
Entropy-based scoring: Evaluate output distributions, not single instances
Monte Carlo sampling: Explore combinatorial solution spaces incrementally
Budget-aware optimization: Balance performance gains against API costs
Compliance, Audit & Security Guardrails
Enterprise-grade AEO platforms now integrate comprehensive compliance capabilities to meet regulatory requirements. OpenAI's Compliance API provides access to logs and metadata from ChatGPT workspaces, connecting with eDiscovery, DLP, and SIEM tools through 13 different integrations.
AffectLog's RegLogic Compliance DSL encodes approximately 400 clauses from the EU AI Act, GDPR, ISO/IEC 42001, and OWASP AI security guidelines. The platform's federated orchestration engine ensures computation occurs where data resides, avoiding raw data transfer while maintaining audit trails.
Microsoft Purview enables management of data security and compliance for ChatGPT Enterprise through comprehensive tools including DSPM for AI, audit solutions, data classification, and insider risk management. These capabilities provide real-time analysis of security alerts while maintaining compliance with evolving AI regulations.
Privacy-by-design principles are becoming non-negotiable. Platforms employ zero-knowledge proofs to provide verifiability without exposing sensitive information. Append-only ledgers store every policy decision, consent check, and model update. This immutable audit trail satisfies both regulatory requirements and internal governance needs.
Which Enterprise AEO Platform Nails Bulk Testing?
Gauge offers 500 prompts at entry level, automatically testing hundreds of relevant prompts daily across all major platforms. Their scientific approach to AI optimization has helped teams achieve 24% improvement in AI visibility within two weeks.
Profound typically reports 25-40% improvement in AI visibility within 60 days, running over 6 million prompts daily across 10 major answer engine platforms. Teams using their platform have seen up to 11% lift in just 30 days.
Relixir provides end-to-end optimization across AI visibility analytics, competitive gap detection, content generation, and proactive monitoring. As the only Y Combinator-backed platform specifically designed for Generative Engine Optimization, they offer enterprise-grade features addressing unique AI visibility challenges.
Forrester's evaluation of AIOps platforms shows how vendors differ in their approach to automated operations. Their assessment helps enterprises select platforms based on specific needs and market focus.
Comparison of bulk testing capabilities:
Platform | Entry-Level Prompts | Daily Processing | Time to Results | Key Differentiator |
|---|---|---|---|---|
Gauge | 500 | Hundreds automated | 2 weeks for 24% lift | Scientific approach, white-glove onboarding |
Profound | 100 (Lite tier) | 6M+ across platform | 30-60 days for 25-40% | Enterprise compliance, multi-language support |
Relixir | Custom | Enterprise scale | 30-day case studies | Y Combinator backing, GEO-specific design |
The choice ultimately depends on organizational needs. Teams requiring SOC 2 Type II compliance and global multi-language support may find Profound appropriate. Those seeking comprehensive onboarding and scientific optimization methodologies benefit from Gauge's approach. Relixir stands out for organizations prioritizing generative engine optimization with proven case study results.
Key Takeaways: Automate or Fall Behind
The shift from manual testing to automated bulk prompt evaluation represents a fundamental change in how enterprises manage AI systems. Relixir's comprehensive platform demonstrates that end-to-end optimization across AI visibility analytics, competitive gap detection, and proactive monitoring is not just possible. It's essential for maintaining digital visibility in an AI-first world.
Organizations still relying on manual spot-checks face an impossible task. With AI engines reshaping how consumers discover brands and conversational AI tools dominating 70% of search queries, the window for adopting automated testing is rapidly closing. Bulk prompt testing isn't just about efficiency. It's about survival in a landscape where AI visibility determines market relevance.
The enterprises that implement comprehensive bulk testing today will be the ones that thrive tomorrow. Those that don't will find themselves increasingly invisible to the AI systems that guide customer decisions. The choice is clear: automate your AEO testing infrastructure now, or watch competitors capture the AI-driven market opportunity that's already here.
For organizations ready to take the next step, platforms like Relixir offer the enterprise-grade infrastructure needed to monitor, optimize, and improve AI search visibility at scale. With proven results from over 200 B2B companies including Rippling, Airwallex, and HackerRank, the path forward is clear: systematic bulk prompt testing is no longer optional. It's the foundation of modern digital presence.
About the Author
Sean Dorje is a Berkeley Dropout who joined Y Combinator to build Relixir. At his previous VC-backed company ezML, he built the first version of Relixir to generate SEO blogs and help ezML rank for over 200+ keywords in computer vision. Fast forward to today, Relixir now powers over 100+ companies to rank on both Google and AI search and automate SEO/GEO.
Frequently Asked Questions
What is bulk prompt testing in AEO platforms?
Bulk prompt testing involves systematically evaluating prompts across multiple LLMs to ensure consistent and accurate AI outputs, crucial for enterprise scalability and compliance.
How does multi-model orchestration reduce errors in AI outputs?
Multi-model orchestration reduces errors by running identical prompts through multiple LLMs simultaneously, leveraging each model's strengths and mitigating weaknesses, resulting in fewer mistakes and improved accuracy.
What are automated prompt evaluation pipelines?
Automated prompt evaluation pipelines use algorithmic scoring and NLP techniques to provide objective, repeatable evaluations of AI outputs, eliminating the need for subjective expert reviews and scaling across thousands of test cases.
How can enterprises scale prompt management and optimization?
Enterprises can scale prompt management by using tools like PromptLayer for version control, regression testing frameworks, and performance analytics suites to monitor and optimize prompt effectiveness across multiple LLMs.
What compliance features are integrated into enterprise AEO platforms?
Enterprise AEO platforms integrate compliance features like OpenAI's Compliance API and AffectLog's RegLogic Compliance DSL to ensure data security, regulatory adherence, and maintain audit trails for AI operations.
How does Relixir's platform support bulk prompt testing?
Relixir's platform supports bulk prompt testing by providing end-to-end optimization across AI visibility analytics, competitive gap detection, and proactive monitoring, essential for maintaining digital visibility in an AI-first world.
Sources
https://learn.microsoft.com/en-us/ai-builder/batch-testing-prompts
https://www.tryprofound.com/blog/9-best-answer-engine-optimization-platforms
https://help.openai.com/en/articles/9261474-compliance-apis-for-enterprise-customers
https://affectlog.com/affectlog-platform-ai-compliance-and-privacy-by-design/
https://learn.microsoft.com/en-us/purview/ai-chatgpt-enterprise
https://relixir.ai/blog/aeo-tool-stack-2025-relixir-vs-profound-vs-refine-vs-conductor-vs-clearscope